
1. ウェブスクレイピングとは?
ウェブスクレイピングとは、ウェブページの情報を自動的に取得・抽出する技術のことを指します。Pythonのライブラリである「BeautifulSoup」を使用することで、簡単にウェブサイトからの情報取得が可能となります。
今回はウェブスクレイピングの練習サイト「Books to Scrape(https://books.toscrape.com/index.html)」を利用して解説をします。
1-1.静的サイトと動的サイトの違い
- 静的サイト: サーバーからクライアント(ユーザーのブラウザ)へ送信される際に、内容が決まっているウェブページ。一度サーバーから送られてくると、内容が変わることは基本的にありません。HTML/CSSのみで構成されていることが多いです。
- 動的サイト: サーバー側で動的に内容が生成・変更されるウェブページ。JavaScriptを使ってブラウザ側でコンテンツが動的に変更されることが多いです。
「BeautifulSoup」は静的サイトの情報取得に適しています。一方、動的サイトの場合、情報が変わることがあります。このような場合、「BeautifulSoup」ではなく「Selenium」を利用することで情報を取得します。
1-2.BeautifulSoupとSelenium
- BeautifulSoup: HTMLやXMLのパーサーで、ウェブページの構造を解析して特定の情報を抽出するのに便利です。主に静的サイトに対して使用します。
- Selenium: ブラウザの自動操作ツール。ブラウザを自動操作することで、動的に変化するページ内容や、JavaScriptで動的にロードされるデータも取得することができます。
動的なウェブページからのデータ抽出を行う際は、Seleniumを使ってブラウザの操作を自動化する必要があります。Seleniumを使用する場合、環境設定など難易度が上がるので、まず「BeautifulSoup」を活用して練習するのがおすすめです。
2. スクレイピングの注意事項と確認事項
ウェブスクレイピングは非常に便利な技術ですが、適切に使用しないと法的トラブルの原因となることがあります。以下に、スクレイピングを行う前に確認すべき主要な3点を挙げて、その詳細な確認方法を解説します。
2-1. WebAPIの有無の確認
- なぜ確認するか?
多くのサイトは、データの正式な取得方法としてWebAPIを提供している場合があります。APIを利用すれば、効率的にデータを取得することができ、サイトへの負荷を減少させることができます。 - どのように確認するか?
ターゲットとなるウェブサイトの「開発者向けページ」や「APIドキュメント」セクションを探してみましょう。また、Googleで「[サイト名] API」のように検索すると、該当するAPIの情報が見つかることがあります。
2-2. Robots.txtの確認
- なぜ確認するか?
robots.txtは、ウェブサイトのルートディレクトリに配置されるファイルで、検索エンジンのロボットなどがサイトをクロールする際のアクセスの可否を指示するものです。スクレイピングを行う際には、このファイルを確認し、許可されていないページをクロールしないよう注意が必要です。 - どのように確認するか?
ウェブサイトのルートにアクセスすることで確認できます。例:http://example.com/robots.txt
このファイルを開き、Disallow:で始まる行を確認しましょう。これがクロールやスクレイピングを禁止されているパスを示しています。
2-3. 利用規約の確認
- なぜ確認するか?
ウェブサイトには、データの使用やアクセスに関する利用規約やポリシーが定められている場合が多いです。これを無視してデータを取得すると、法的な問題に発展する可能性があります。 - どのように確認するか?
主にサイトのフッター部分に「利用規約」のリンクが配置されていることが多いです。このセクションを開き、データの使用やアクセスに関する項目を注意深く読むようにしましょう。
3. 実際のコード解説
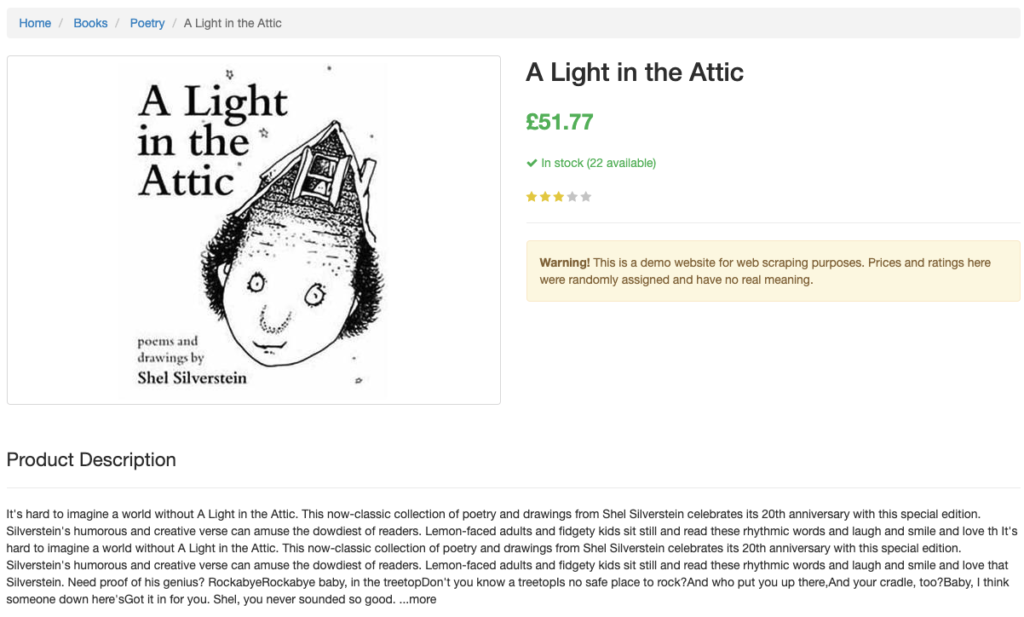
今回はウェブスクレイピングの練習サイト「Books to Scrape(https://books.toscrape.com/index.html)」の「A Light in the Attic」のページに関わる情報取得を解説します。
まず最初に必要なライブラリ「BeautifulSoup」をインポートします。
import requests from bs4 import BeautifulSoup次に、取得したいウェブページのURLを指定します。
book_url = "http://books.toscrape.com/catalogue/tipping-the-velvet_999/index.html"その後、requestsライブラリを使ってウェブページの内容を取得します。
response = requests.get(book_url)BeautifulSoupを使用して、取得したHTMLを解析可能な形に変換します。
soup = BeautifulSoup(response.content, "html.parser")そして、指定したタグやクラスを用いて情報を抽出します。
title = soup.h1.get_text(strip=True)
price = soup.find("p", class_="price_color").get_text(strip=True)
availability = soup.find("p", class_="availability").get_text(strip=True)
description = soup.select("meta[name='description']")[0]["content"].strip()最後に、取得した情報を表示します。
print(f"タイトル: {title}")
print(f"価格: {price}")
print(f"在庫状況: {availability}")
print(f"説明: {description}")
無事に情報を取得することに成功しました。今回は1ページの情報取得でしたが、複数ページに渡る情報取得の場合、for文を利用してスクレイピングを実行します。