
前提
IBMのHR Analytics Employee Attrition & Performanceデータセットを使用して、従業員の退職予測モデルを作成する方法を解説します。
このデータセットは、従業員の個々の詳細情報とそれに基づく退職の可能性を表しています。ここで2つの機械学習アルゴリズム、「決定木」と「ランダムフォレスト」を用いてモデルを構築します。
決定木とランダムフォレストは、多くの場合、機械学習の問題に対して単純でありながら非常に強力なモデルであるという理由から選択されます。それぞれのモデルの特性を以下に示します。
- 決定木:決定木は単純さと解釈可能性の高さで知られています。決定木は「if-then」ルールの連続として表現することができ、この特性により、モデルがどのように予測を行っているのかを容易に理解することができます。これはビジネス上の意思決定や結果の説明において非常に有用です。
- ランダムフォレスト:ランダムフォレストは、複数の決定木を組み合わせて動作します。これにより、各決定木の過学習を抑制し、より堅牢な予測を行うことができます。ランダムフォレストは一般的に、単一の決定木よりも高い予測精度を提供します。
しかし、ランダムフォレストの一部の欠点は、多数の決定木を使用するため、モデルが複雑になり、結果を解釈することが難しくなることです。ただし、その精度と性能の優れたバランスにより、多くの機械学習の問題に対して初期のベンチマークとして選ばれることが多いです。
今回の退職者予測の問題では、決定木とランダムフォレストの両方で特徴量の重要度を比較することで、どの特徴量が目的変数に対して最も影響力があるかを洞察します。
データの前処理
まず初めに、必要なライブラリをインポートし、データを読み込みます。
import pandas as pd
# データの読み込み
hr_data = pd.read_csv('/content/hrdata.csv')
# データの最初の5行を表示
hr_data.head()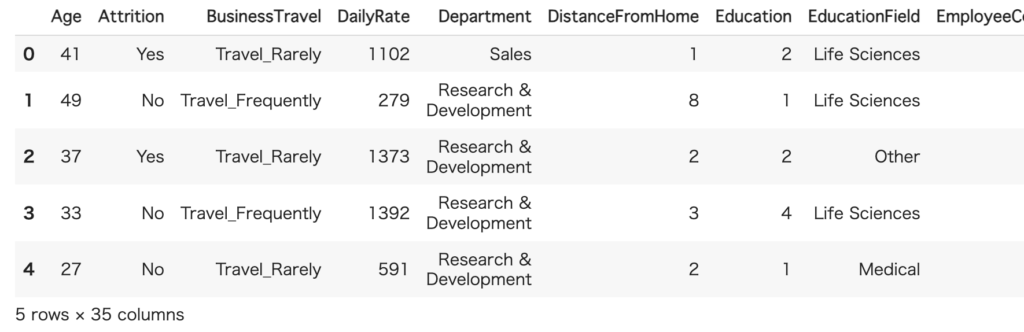
次にデータの全体感を把握するために各列の統計量を調査します。
# 各統計量を調査
hr_data.describe(include='all')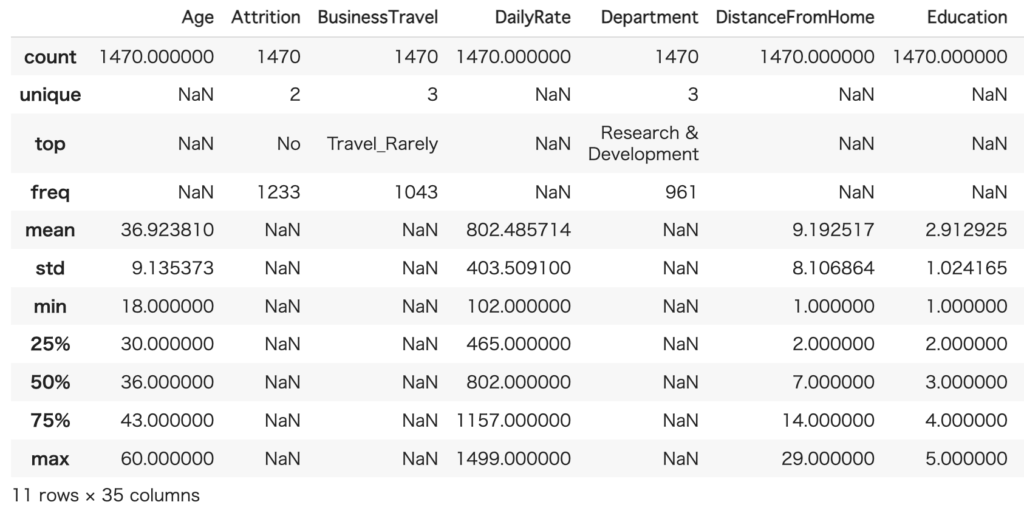
hr_data.isnull().sum()
データには欠損値がないことが確認されました。データに欠損値があると、それがモデルの学習と予測の精度に大きな影響を与える可能性があります。以下、その理由について詳しく説明します。
- モデルの学習: ほとんどの機械学習アルゴリズムは、欠損値が存在するときに適切に動作しません。つまり、欠損値をそのままにしておくと、モデルの学習自体が不可能になる場合があります。
- バイアスの導入: 欠損値を無視して削除したり、適当な値で補完したりすると、データにバイアスが導入され、結果的にモデルの予測精度が下がる可能性があります。
- 情報の損失: 欠損値を持つレコードを単純に削除すると、他の特徴量で完全な情報を持つレコードも同時に失われ、これがモデルの学習に必要な情報の損失につながります。
そのため、欠損値を適切に処理することが重要です。欠損値の処理方法には様々なものがあり、平均値、中央値、最頻値などで補完する方法や、特定の値で補完する方法(例えば、-1や9999など)、あるいは高度な手法として、他の変数を利用した回帰補間や、機械学習を用いて欠損値を予測する方法などがあります。
しかし、これらの方法を適用する前に、データが欠損している理由を理解し、それがランダムなものなのか、あるいは何らかのパターンやシステマティックな原因があるのかを評価することが重要です。それによって、最も適切な欠損値の取り扱い方を決定することができます。
意味のない列(’EmployeeCount’, ‘EmployeeNumber’, ‘Over18’, ‘StandardHours’)を削除します。35列から31列に減ったことが画像から確認することができます。
# 無関係な列を削除
hr_data = hr_data.drop(['EmployeeCount', 'EmployeeNumber', 'Over18', 'StandardHours'], axis=1)
# 最初の5行を表示
hr_data.head()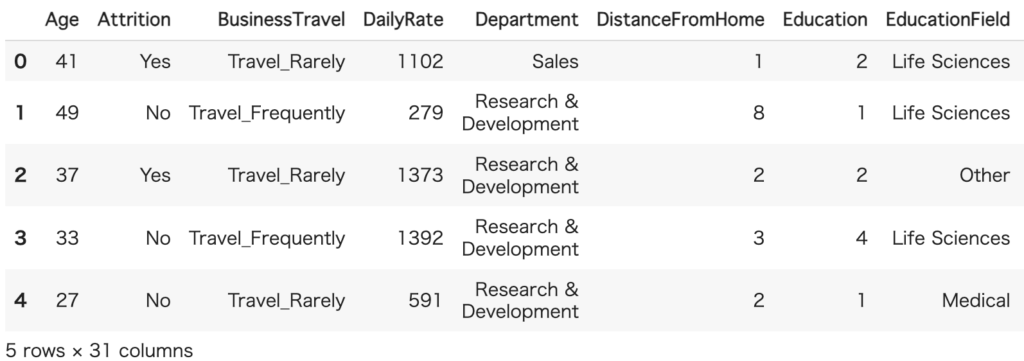
機械学習モデルの構築:決定木
次に、決定木分類器を使用してモデルを作成します。モデル作成のため、データセットのカテゴリ変数を数値に変換し、その後データを特徴量(X)とターゲット(y)に分割します。
データを70%のトレーニングセットと30%のテストセットに分割した後、決定木分類器を初期化し、トレーニングデータにフィットさせます。そしてテストデータを使用して、目的変数(ここで退職するかどうか)を予測します。
# 必要なモジュールのインポート
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
# データの読み込み
hr_data = pd.read_csv('/content/hrdata.csv')
# 不要な列を削除
hr_data = hr_data.drop(['EmployeeCount', 'EmployeeNumber', 'Over18', 'StandardHours'], axis=1)
# ラベルエンコーダーの初期化
labelencoder = LabelEncoder()
# カテゴリ変数のリスト
categorical_vars = ['Attrition', 'BusinessTravel', 'Department', 'EducationField', 'Gender', 'JobRole', 'MaritalStatus', 'OverTime']
# カテゴリ変数を数値に変換
for var in categorical_vars:
hr_data[var] = labelencoder.fit_transform(hr_data[var])
# データを特徴量(X)とターゲット(y)に分割
X = hr_data.drop('Attrition', axis=1)
y = hr_data['Attrition']
# データをトレーニングセット(70%)とテストセット(30%)に分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
# 決定木分類器を初期化
dt_model = DecisionTreeClassifier(random_state=1)
# モデルをトレーニングデータにフィット
dt_model.fit(X_train, y_train)
# テストデータで目的変数を予測
y_pred_dt = dt_model.predict(X_test)
# モデルの精度を計算
accuracy_dt = accuracy_score(y_test, y_pred_dt)
# 分類レポートを計算
class_report_dt = classification_report(y_test, y_pred_dt)
# 混同行列を計算
conf_matrix_dt = confusion_matrix(y_test, y_pred_dt)
accuracy_dt, class_report_dt, conf_matrix_dt
精度:0.7732426303854876
比較的精度の高い結果を出すことができました。後ほどランダムフォレストと精度を比較してみます。また、特徴量の重要度を取得し、データフレームで可視化します。そして決定木を描画します。
# 特徴の重要度を取得
feature_importances_dt = dt_model.feature_importances_
# 可視化のためのデータフレームを作成
importances_df_dt = pd.DataFrame({
'Feature': X_train.columns,
'Importance': feature_importances_dt
})
# 重要度でデータフレームをソート
importances_df_dt = importances_df_dt.sort_values(by='Importance', ascending=False)
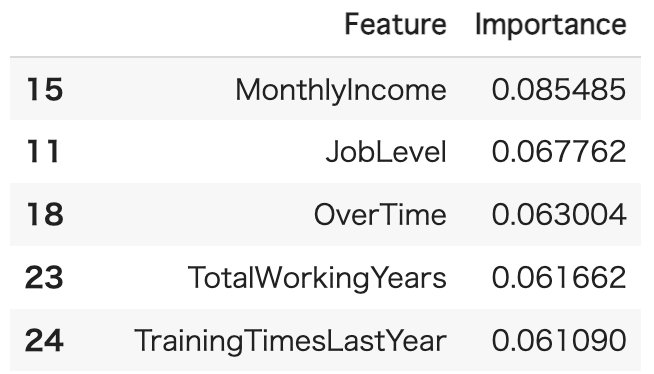
importances_df_dt特徴量で重要度が高いベスト3は、MonthlyIncome・JobLevel・OverTimeとなっており、後ほどランダムフォレストとの重要度の違いを見てみましょう。
決定木を可視化してみます。可視化した結果は画像の通りで、文字が見えないくらいかなり深い構造になっており、過学習を起こしている可能性が高いです。深さを調整するなどして、精度を高める工夫をすることができます。
from sklearn import tree
import matplotlib.pyplot as plt
# Set the size of the plot
plt.figure(figsize=(30,20))
# Create a decision tree plot
tree.plot_tree(dt_model,
feature_names=X_train.columns,
class_names=['No Attrition', 'Attrition'],
filled=True)
# Show the plot
plt.show()
機械学習モデルの構築:ランダムフォレスト
ランダムフォレストは、多数の決定木を組み合わせて一般的な予測を得るためのアンサンブル学習法です。これにより、モデルのバリアンスが低下し、過学習を防ぐことができます。
同様の前処理の後、ランダムフォレスト分類器を初期化し、トレーニングデータにフィットさせます。そしてテストデータを使用して予測を行い、モデルの精度を計算します。また、各特徴量の重要度を取得し、それをデータフレームで可視化します。
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
# ラベルエンコーダーを初期化
labelencoder = LabelEncoder()
# カテゴリー変数のリスト
categorical_vars = ['Attrition', 'BusinessTravel', 'Department', 'EducationField', 'Gender', 'JobRole', 'MaritalStatus', 'OverTime']
# カテゴリー変数を変換
for var in categorical_vars:
hr_data[var] = labelencoder.fit_transform(hr_data[var])
# データを特徴量(X)とターゲット(y)に分割
X = hr_data.drop('Attrition', axis=1)
y = hr_data['Attrition']
# データを訓練セット(70%)とテストセット(30%)に分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
# ランダムフォレスト分類器を初期化
rf_model = RandomForestClassifier(n_estimators=100, random_state=1)
# モデルを訓練データに適合
rf_model.fit(X_train, y_train)
# テストデータのターゲット変数を予測
y_pred = rf_model.predict(X_test)
# モデルの精度を計算
accuracy = accuracy_score(y_test, y_pred)
# 分類レポートを計算
class_report = classification_report(y_test, y_pred)
# 混同行列を計算
conf_matrix = confusion_matrix(y_test, y_pred)
accuracy, class_report, conf_matrix
精度:0.8367346938775511
決定木よりも高い精度を出すことができました。このモデルを利用して退職者の予測をすると、83%の確率の精度で算出できるので十分なパフォーマンスを発揮できます。
さらに精度の向上を図る場合、パラメータのチューニングをすることで精度を上げることができる可能性があります。また他の手法も並行して試すことで比較をすることも一つの有効な方法になります。
# 特徴量の重要度を取得
feature_importances = rf_model.feature_importances_
# 可視化のためのデータフレームを作成
importances_df = pd.DataFrame({
'Feature': X_train.columns,
'Importance': feature_importances
})
# 重要度によってデータフレームを並び替え
importances_df = importances_df.sort_values(by='Importance', ascending=False)
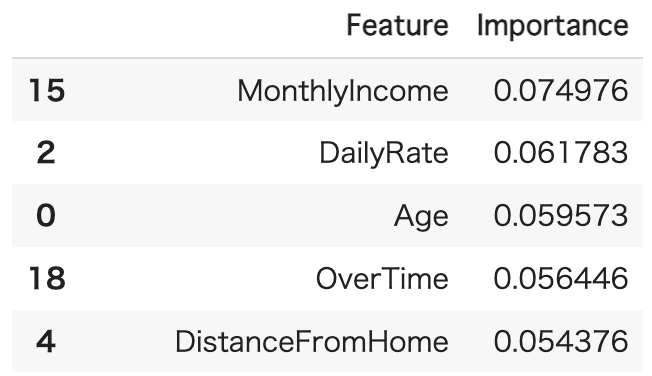
importances_df特徴量で重要度が高いベスト3は、MonthlyIncome・DailyRate・Age。決定木と同様にMonthlyIncome(月給)が一番重要度の高い指標で、外資系であることを考慮すると納得感のある結果かなと考えられます。
まとめ
IBMのHRデータセットを用いて、従業員が退職するか否かを予測するモデルを構築する方法を解説しました。
今回は、2つの異なる機械学習アルゴリズム、決定木とランダムフォレストを用いて、モデルを作成し比較しています。この結果を用いて、人事部門が退職リスクの高い従業員を早期に特定し、適切な措置を講じることが出来ます。