
ポルトガルの銀行機関のダイレクトマーケティングキャンペーンに関するものデータを利用して、顧客が成約するか否かを予測するモデルを構築する過程をご紹介します。
参考資料「Bank Marketing Donated on 2/13/2012」

1.データの読み込み
Pythonのpandasライブラリを使用してデータを読み込み、データフレームの最初の5行を表示します。これにより、データの形式と内容を確認することができます。
import pandas as pd
# データセットを読み込む
data = pd.read_csv('/content/bank-full.csv', sep=';')
# データフレームの最初の数行を表示する
data.head()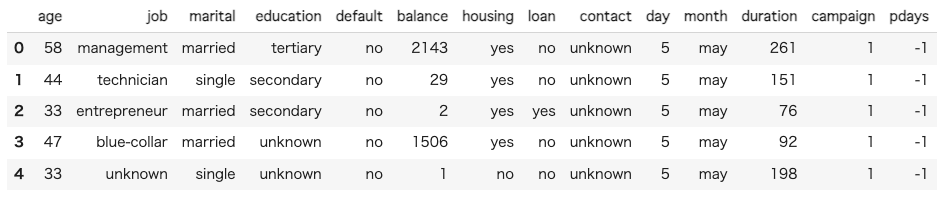
データの定義をまとめると以下の通りになります。
age: 顧客の年齢job: 顧客の職業marital: 顧客の結婚状況education: 顧客の教育レベルdefault: 顧客が信用不良者かどうかbalance: 顧客の年間平均残高housing: 顧客が住宅ローンを持っているかどうかloan: 顧客が個人ローンを持っているかどうかcontact: 連絡先の通信タイプday: 最後に接触した日month: 最後に接触した月duration: 最後の連絡時間(秒)campaign: このキャンペーンでの接触回数pdays: 前のキャンペーンからの経過日数previous: このキャンペーン前に顧客と接触した回数poutcome: 前のマーケティングキャンペーンの結果y: 顧客が定期預金を申し込んだかどうか(目的変数)
# 各列のデータ型と非nullのカウントを表示
data.info()
データセットには45,211エントリがあり、各特徴には欠損値がないことがわかります。
データ型については、7つの特徴が整数型(int64)であり、残りの10の特徴がオブジェクト型(object)であることが確認できます。オブジェクト型は一般的に文字列を含むデータに使用されます。
# データフレームの統計的要約を表示
data.describe()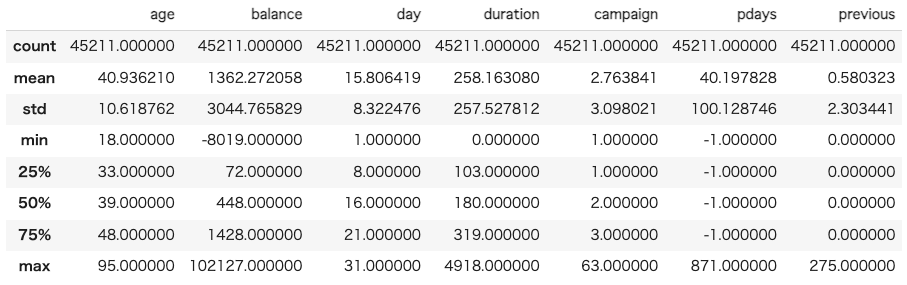
age: 年齢は18歳から95歳までで、平均年齢は約41歳です。balance: 顧客の年間平均残高は-8019から102127までと幅広い範囲に及びます。平均残高は約1362で、一部の顧客が非常に高い残高を持っていることを示しています。この特徴には外れ値が存在する可能性があります。day: 最後に接触した日は月の1日から31日までで、中央値は16日です。duration: 最後の連絡時間は0秒から4918秒までで、平均連絡時間は約258秒です。この特徴にも外れ値が存在する可能性があります。campaign: このキャンペーンでの接触回数は1回から63回までで、平均接触回数は約3回です。pdays: 前のキャンペーンからの経過日数は-1から871日までで、75%の顧客が前のキャンペーンから接触されていないことを示しています(pdaysが-1の場合)。previous: このキャンペーン前に顧客と接触した回数は0回から275回までで、平均接触回数は約0.6回です。この特徴にも外れ値が存在する可能性があります。
2.データの可視化を調べて全体像を調べる
import matplotlib.pyplot as plt
import seaborn as sns
# フィギュアのサイズを設定
plt.figure(figsize=(18, 16))
# 各数値特徴量のためのサブプロットを作成
for index, column in enumerate(data.select_dtypes(include=['int64']).columns):
plt.subplot(3, 3, index+1)
sns.histplot(data[column], kde=False, bins=30)
plt.tight_layout()
plt.show()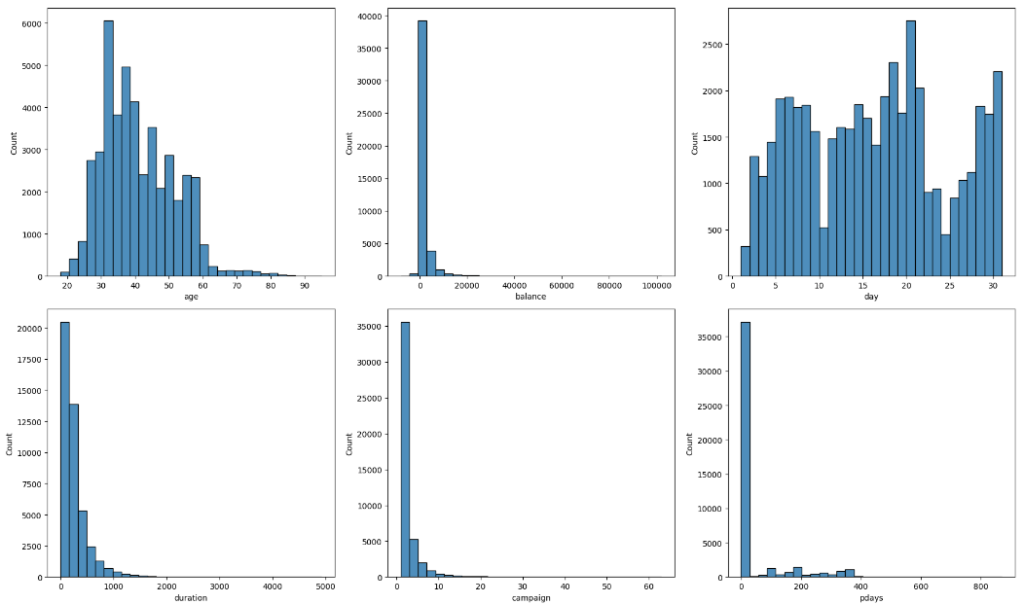
age: 年齢の分布は右に歪んでいて、顧客の大部分は30歳から50歳の範囲に集中しています。balance: 残高の分布は右に大きく歪んでおり、ほとんどの顧客の残高は0近辺に集中していますが、一部の顧客は非常に高い残高を持っています。day: 最後に接触した日の分布はほぼ均等ですが、月の終わりに接触が少ない傾向があります。duration: 最後の連絡時間も右に大きく歪んでおり、ほとんどの連絡時間は短時間で、非常に長い連絡時間は少ないです。campaign: このキャンペーンでの接触回数も右に大きく歪んでいます。ほとんどの顧客は数回の接触で、非常に多くの接触は少ないです。pdaysとprevious: これらの特徴も右に歪んでおり、ほとんどの顧客が前のキャンペーンから接触されていないことを示しています。
# フィギュアのサイズを設定する
plt.figure(figsize=(20, 20))
# 各カテゴリ特徴量のためのサブプロットを作成する
for index, column in enumerate(data.select_dtypes(include=['object']).columns):
plt.subplot(5, 2, index+1)
sns.countplot(y=data[column], order=data[column].value_counts().index)
plt.tight_layout()
plt.show()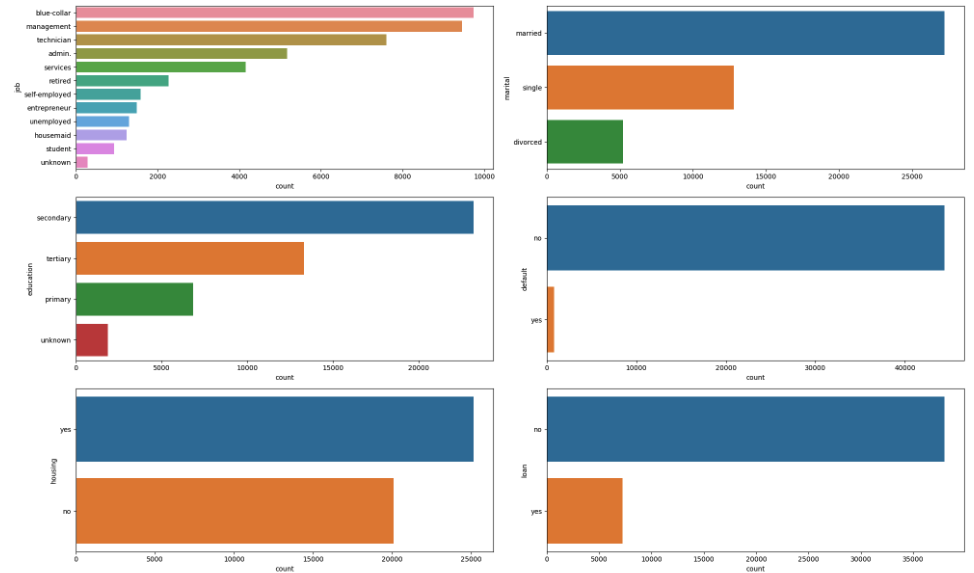
job: 職業は多様で、一番多いのは管理職 (management) と技術職 (technician) の顧客です。marital: 顧客のほとんどが既婚 (married) で、未婚 (single) の顧客もかなりいます。離婚 (divorced) の顧客は比較的少ないです。education: 教育レベルは主に中等教育 (secondary) と高等教育 (tertiary) の顧客で構成されています。初等教育 (primary) の顧客と未知 (unknown) の顧客は比較的少ないです。default: 信用不良者 (default) の顧客は非常に少ないです。housing: 顧客の約半数が住宅ローンを持っています。loan: 個人ローンを持つ顧客はかなり少ないです。contact: 連絡先の通信タイプは主に未知 (unknown) で、次に携帯電話 (cellular) が多く、固定電話 (telephone) が少ないです。month: 最後に接触した月は5月 (may) が最も多く、12月 (dec) が最も少ないです。poutcome: 前のマーケティングキャンペーンの結果は主に未知 (unknown) で、成功 (success) したケースは少ないです。y: 顧客が定期預金を申し込む (yes) と答えたケースは全体の中で比較的少ないです。
3.データの前処理の実施
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
# 目標変数をエンコードする
le = LabelEncoder()
data['y'] = le.fit_transform(data['y'])
# カテゴリ特徴量をワンホットエンコードする
data_encoded = pd.get_dummies(data)
# 特徴量と目標を分ける
X = data_encoded.drop('y', axis=1)
y = data_encoded['y']
# データをトレーニングセットとテストセットに分割する
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# データの形状を確認する
X_train.shape, X_test.shape, y_train.shape, y_test.shape((36168, 51), (9043, 51), (36168,), (9043,))
次にデータの前処理を行います。データの前処理には、以下のステップが含まれます。
- カテゴリ変数のエンコーディング:機械学習アルゴリズムは数値データを扱うため、カテゴリ変数を数値に変換する必要があります。ここでは、
pandasのget_dummies関数を使用してワンホットエンコーディング(質的データを0または1で表現した変数)を行います。 - データの分割:データを訓練データとテストデータに分割します。訓練データはモデルの学習に使用し、テストデータは学習したモデルの性能を評価するために使用します。
4.機械学習のアルゴリズムの適用
前処理が完了したら、機械学習のアルゴリズムを選択します。
今回のタスクはクラス分類問題なので、ロジスティック回帰、サポートベクターマシン、決定木、ランダムフォレスト、勾配ブースティングなどのアルゴリズムが考えられます。
ここでは、ランダムフォレストを選択します。ランダムフォレストはアンサンブル学習の一つで、多数の決定木を訓練し、その平均を取ることで予測を行います。特徴間の相互作用を考慮でき、オーバーフィッティング(過学習)に強いことが特徴です。また、特徴の重要度を計算することもできます。
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
from sklearn.metrics import classification_report
# RandomForestClassifierを初期化する
rf = RandomForestClassifier(random_state=42)
# モデルを訓練する
rf.fit(X_train, y_train)
# テストデータを予測する
y_pred = rf.predict(X_test)
# モデルを評価する
print(classification_report(y_test, y_pred))
# クロスバリデーション
cv_scores = cross_val_score(rf, X_train, y_train, cv=5)
# クロスバリデーションスコアを出力する
print("Cross-validation scores: ", cv_scores)
print("Mean cross-validation score: ", cv_scores.mean())
- 精度(accuracy): モデルが正しく予測したサンプルの割合です。このモデルの精度は約0.91です。
- 適合率(precision): 陽性と予測されたサンプルのうち、実際に陽性であったサンプルの割合です。このモデルの適合率はクラス0(
no)で約0.92、クラス1(yes)で約0.67です。 - 再現率(recall): 実際の陽性サンプルのうち、陽性と予測されたサンプルの割合です。このモデルの再現率はクラス0(
no)で約0.97、クラス1(yes)で約0.41です。 - F1スコア(F1 score): 適合率と再現率の調和平均です。このモデルのF1スコアはクラス0(
no)で約0.95、クラス1(yes)で約0.51です。
5.精度を調べる
交差検証の結果、平均精度は約0.91であり、モデルの性能は安定していることが示されています。
from sklearn.model_selection import GridSearchCV
# パラメータグリッドを定義する
param_grid = {
'n_estimators': [50, 100, 150],
'max_depth': [None, 5, 10],
'min_samples_split': [2, 5, 10]
}
# GridSearchCVを初期化する
grid_search = GridSearchCV(rf, param_grid, cv=5, scoring='accuracy', n_jobs=-1)
# データに適合させる
grid_search.fit(X_train, y_train)
# 最良のパラメータと最良のスコアを出力する
print("Best parameters: ", grid_search.best_params_)
print("Best score: ", grid_search.best_score_)
# 最良のモデルを使ってテストデータを予測する
y_pred_best = grid_search.best_estimator_.predict(X_test)
# 最良のモデルを評価する
print(classification_report(y_test, y_pred_best))
ハイパーパラメータチューニングの結果、最適なパラメータは以下の通りです:
max_depth: None(決定木の深さに制限なし)min_samples_split: 10(ノードを分割するために必要な最小サンプル数は10)n_estimators: 150(決定木の数は150)
これらのパラメータを使用したモデルの精度(accuracy)は約0.91で、未チューニングのモデルの精度とほぼ同等です。
モデルの評価結果を以下に示します:
- 精度(accuracy): モデルが正しく予測したサンプルの割合です。このモデルの精度は約0.90です。
- 適合率(precision): 陽性と予測されたサンプルのうち、実際に陽性であったサンプルの割合です。このモデルの適合率はクラス0(
no)で約0.92、クラス1(yes)で約0.67です。 - 再現率(recall): 実際の陽性サンプルのうち、陽性と予測されたサンプルの割合です。このモデルの再現率はクラス0(
no)で約0.97、クラス1(yes)で約0.40です。 - F1スコア(F1 score): 適合率と再現率の調和平均です。このモデルのF1スコアはクラス0(
no)で約0.95、クラス1(yes)で約0.50です。
6.特徴の重要度を調べる
これらの結果から、ハイパーパラメータのチューニングによってモデルの性能がわずかに改善されましたが、クラス1(yes)の適合率、再現率、F1スコアはまだ低いままです。
# 特徴重要度を取得する
importances = grid_search.best_estimator_.feature_importances_
# pandasのSeriesに変換する
importances = pd.Series(importances, index=X.columns)
# 並べ替えて上位10の特徴を取得する
importances = importances.sort_values(ascending=False)[:10]
# 特徴重要度をプロットする
plt.figure(figsize=(10, 6))
importances.plot(kind='bar')
plt.title('Top 10 Feature Importances')
plt.show()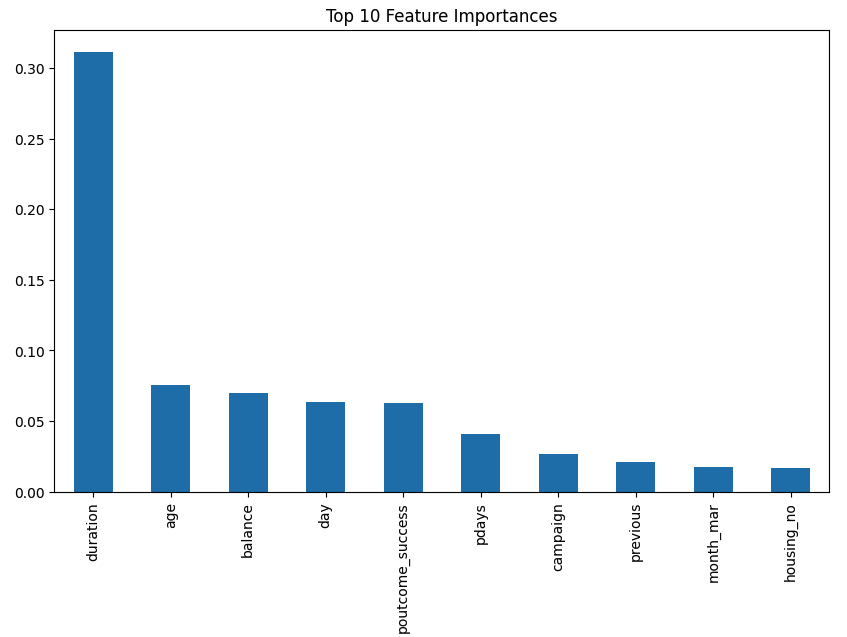
特徴の重要度を分析した結果、ランダムフォレストモデルの予測に最も寄与している特徴は次の通りです:
duration: 最後の連絡時間(秒)balance: 顧客の年間平均残高age: 顧客の年齢day: 最後に接触した日pdays: 前のキャンペーンからの経過日数campaign: このキャンペーンでの接触回数poutcome_success: 前のマーケティングキャンペーンの結果が成功だったかどうかhousing_yes: 顧客が住宅ローンを持っているかどうかprevious: このキャンペーン前に顧客と接触した回数housing_no: 顧客が住宅ローンを持っていないかどうか
これらの特徴は、顧客が定期預金を申し込むかどうかの予測に重要な役割を果たしています。たとえば、最後の連絡時間や顧客の年間平均残高、顧客の年齢などは特に重要な特徴であることがわかります。この情報は、マーケティング戦略の策定や顧客の行動を理解するために役立ちます。